Veröffentlicht am 22.06.2024 von Alphalines
Viel hilft viel – was in den Anfangszeiten der SEO noch galt und in kreativen Auswüchsen wie Keyword-Stuffing,
fünf H1 auf einer Seite oder Link-Spam mündete, funktioniert schon lange nicht mehr. Google wird jeden
Tag besser und anspruchsvoller und lässt sich ungern mit Inhalten oder Signalen bombardieren, die
qualitativ minderwertig sind. Vielmehr verfolgt Google weiter sein ureigenes Ziel: dem Nutzer das eine,
beste Ergebnis für seine Suchanfrage zu liefern.
Wie Googles ehemaliger Pressesprecher Stefan Keuchel bereits 2010 sinngemäß zu mir sagte:
„Die Tatsache, dass wir 100.000 Ergebnisse zu einer Suche zurückliefern, ist für uns kein gutes Zeichen.
Es ist ein Zeichen, dass wir es noch immer nicht schaffen, dieses eine, richtige Ergebnis zu liefern,
das dieser spezielle Nutzer in exakt dieser Sekunde im Rahmen seiner Suchhistorie erhalten möchte.“ Ja, das
klingt ein bisschen scary. Aber weist deutlich den Weg, wohin die Reise schon sehr lange gehen soll.
Und diese Reise sollte im Idealfall nicht von Web-Publishern behindert werden, die Google immer mehr
und mehr Content und URLs zum Fraß vorwerfen, von denen möglicherweise nur ein Bruchteil überhaupt eine Relevanz hat.
Wie Bastian Grimm zudem treffend bei seiner Keynote auf der SEOkomm 2022 in Salzburg
formulierte: „Crawling kostet Geld.“ Nicht von ungefähr stellen Google & Co. etwaige Instrumente
von Ping bis XML Sitemap zur Verfügung, um den Suchgiganten bei der Erfassung der korrekten Inhalte
zu assistieren. Denn auch Suchmaschinen sind daran interessiert, die eigenen Ressourcen zu schonen
und schlicht Geld zu sparen.
Was gilt es also, als guter SEO zu tun? Neben den üblichen Hausaufgaben wie Suchintention
identifizieren und bedienen, eine technisch saubere Seite bauen, organisch Backlinks generieren
und Verticals triggern, steht ein Job meist noch viel zu weit unten auf der To Do Liste: aufräumen.
Ein Ziel in der SEO sollte sein, dafür zu sorgen, dass nur die URLs und Inhalte im Index landen,
die dort auch wirklich landen sollen. Dabei helfen einige Tools und Kniffe, die im Folgenden vorgestellt werden.
Die XML Sitemap: direkte Kommunikation mit Google
Die XML Sitemap ist ein wunderbares Instrument, um direkt mit Google darüber zu kommunizieren,
welche Inhalte im Index landen sollten. Zudem bekommt man konkretes Feedback, bei welchen Inhalten
es möglicherweise Schwierigkeiten gibt.

Beispiel für eine XML Sitemap. Quelle:
Sitemap erstellen und einreichen
Um diese Feedbackmöglichkeiten ideal auszunutzen, hilft es, granulare XML Sitemaps aufzubauen und entsprechend
in der Search Console zu hinterlegen. Eine Möglichkeit dafür ist es beispielsweise, XML Sitemaps nach Template
aufzuteilen, also eine XML Sitemap für Produktseiten, eine für Kategorie-Seiten und eine für Ratgeberartikel.
Über all diesen Unter-Sitemaps liegt die Index-Sitemap, die eine Auflistung aller bestehenden Sitemaps darstellt.
Mit einer granularen Vorgehensweise kann man auf einen Blick erkennen, ob Google beispielsweise Probleme
damit hat, die Produkt-Landingpages zu indexieren oder ob viele der Kategorie-Seiten ignoriert werden.
Doch bereits eine Quick and Dirty XML Sitemap, die automatisch generiert wird (es gibt dafür
viele Freetools im Netz oder entsprechende Plugins fürs CMS, beispielsweise www.xml-sitemaps.com
oder das Yoast SEO Plugin für WordPress), hilft ungemein bei der SEO. Selbstverständlich muss man
insbesondere bei der XML Sitemap darauf achten, dass man Google und anderen Suchmaschinen keine URLs
darin präsentiert, die nicht indexrelevant sind. Mit anderen Worten: URLs mit 301 oder 404 Statuscode
oder Thin Content (wir kommen später darauf zurück) sollten gar nicht erst in der XML Sitemap
gelistet werden. Dafür sollten indexrelevante Bilder und Videos entsprechend mitaufgelistet werden,
um auch deren Indexierung zu pushen. Für beide Medien stehen zusätzlich separate XML Sitemap
Formate zur Verfügung, die das Übermitteln detaillierter Informationen zu den jeweiligen Medien ermöglichen.
Natürlich gilt auch hier: Weniger ist mehr. Es hilft beispielsweise nicht, für jeden URL-Eintrag
in der XML Sitemap einen
Wir wir schon an anderer Stelle häufig gesehen haben (noch immer versuchen Webmaster,
mit einem Meta Tag Revisit-After Google dazu zu bringen, sich täglich ihre Seite anzusehen – nein,
das funktioniert so nicht), lässt sich Google nicht vorschreiben, wie es URLs behandeln und priorisieren soll.
Gerade dafür ist der hauseigene Algorithmus ja da. Im Fall der XML Sitemap hat John Mueller
ausdrücklich gesagt, dass eine Angabe wie
Bitte nicht verwechseln: die robots.txt
Für die Indexierung gerne verwendet, aber leider völlig ungeeignet ist die robots.txt.
Die robots.txt enthält Anweisungen für unterschiedlichste Crawler, welche Seiten im Crawling
erfasst werden sollen. Die im Root der Domain abgelegte Datei kann beispielsweise ganze
Verzeichnisse für einen Bot sperren, so dass dieser dieses Verzeichnis gar nicht erst fürs Crawling aufruft.
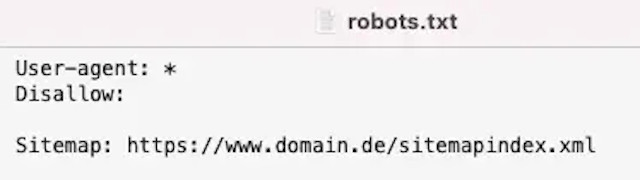
Beispiel für eine robots.txt Datei
Das bedeutet allerdings nicht, dass Seiten, die vom Crawling ausgeschlossen werden, auch automatisch
nicht im Index landen. Oft passiert sogar Gegenteiliges, was dann zu Fehlern in der Indexierungssteuerung
führen kann. Ein Beispiel: Wenn ich eine Seite A per 301 Redirect dauerhaft auf eine Seite B weiterleite,
das Crawling von Seite A aber per robots.txt untersage, kann es passieren, dass der Bot den Redirect der
Seite nicht erfasst, da der HTTP Header der betroffenen Datei nicht ausgelesen wird. Die URL landet trotz
aktiver Weiterleitung im Index. Ein ausgesprochen unschönes Ergebnis. Das Gleiche gilt für „noindex“
Anweisungen im HTML Quelltext, auf die wir im nächsten Abschnitt genauer eingehen. Auch diese Anweisung
wird vom Bot gar nicht erst gesehen, wenn er die Seite nicht crawlen darf. Kurzum: Explizite Bot-Anweisungen
verpuffen leider wirkungslos, wenn ich per robots.txt festlege, dass der Bot die Seite gar nicht erst crawlen darf.
Please, noindex me!
Unabhängig von externen Files wie XML Sitemap und robots.txt kann ich als HTML Dokument
selbstverständlich auch direkt sagen, dass ich nicht indexiert werden möchte. Die HTML
Anweisung im Header einer HTML Datei kommuniziert
deutlich, dass diese Seite nicht für die Indexierung durch eine Suchmaschine gedacht ist.
Dieser sogenannte Robots-Meta-Tag steht Default auf “index“, daher muss diese Angabe nicht
zwingend hinterlegt werden. Zusätzliche Angaben wie “follow“ beispielsweise weisen Bots dazu an,
den Links auf einer Seite zu folgen und Linkjuice weiterzugeben. Interessant ist in diesem Fall
die Kombination aus “noindex,follow“, da dieser Robots-Meta-Tag eine Seite von der
Indexierung ausschließt, zugleich dem Bot aber mitgibt, dass die auf der Seite befindlichen
Links weiterhin beachtet werden sollten.
Dateien, die keinen beschreibbaren HTML Header besitzen, wie beispielsweise PDF oder
Bilddateien, können in diesem Fall auf den HTTP-Header X-Robots-Tag zurückgreifen.
In dieser HTTP Header Anweisung können alle Anweisungen hinterlegt werden, die auch
in dem zuvor beschriebenen Robots-Meta-Tag vorkommen können.
Ping me on, just when you go-go
Nicht nur die XML Sitemap bietet sich dafür an, Suchmaschinen über zu indexierende
Inhalte zu informieren. Ein ganz altes und noch immer nutzbares Instrument zur
Indexierungssteuerung ist der Ping. In der Search Console kann ich beispielsweise
einzelne URLs zur erneuten Überprüfung einreichen. Wie üblich unterstützt Google
hier kein Spamming. Es nutzt also gar nichts, eine neue URL täglich neu zu pingen,
in der Hoffnung einer schnellen Indexierung. In ihrem Hilfeartikel weist Google
explizit darauf hin, dass für das Einreichen neuer URLs ein bestimmtes Kontingent
gilt, das nicht durch häufiges Auf-sich-aufmerksam-machen ausgeweitet werden kann.
Gegenläufig kann ich über die Search Console auch einzelne URLs entfernen lassen.
Mit dem URL Removal Tool kann ich veranlassen, dass einzelne URLs nicht mehr im
Google Index auffindbar sind. Allerdings ist dieses Vorgehen temporär, eine
dauerhafte Entfernung der URL ist über dieses Tool nicht möglich. Um dies zu erreichen,
müssen weitere Schritte wie die bereits beschriebene „noindex“ Anweisung oder
das Senden der Statuscodes 404 oder 410 unternommen werden.
Google Hacking: Was ist bereits indexiert?
Google Hacking klingt tatsächlich deutlich dramatischer, als es in Wirklichkeit ist.
Die Headline hat aber, neben dem durchschaubaren Versuch, Aufmerksamkeit zu erregen,
einen ganz realen Hintergrund. Das Buch „Google Hacking“ von Johnny Long (2005) war
zum damaligen Erscheinungszeitpunkt eine schöne Anleitung dafür, wie man Inhalte im
Google Index aufspüren konnte, die dort definitiv nichts verloren hatten. Dies war
nicht nur für SEO relevant: Sensible Daten landeten immer wieder im noch nicht
ausgereiften Google Index und machten Unternehmen für entsprechende Angriffe verletzbar.
Seit dieser Zeit ist Google immer besser geworden und einfache Abfragen, mit
deren Hilfe man Passwörter und Ähnliches abfragen konnte, funktionieren schon
lange nicht mehr. Doch noch immer existieren bestimmte Abfragen mittels Suchoperatoren,
die das Durchsuchen des Indexes und damit die Indexierungssteuerung deutlich erleichtern.
Hier einige der wichtigsten Anweisungen:
Site:domain.de – mit dieser Abfrage werden alle Seiten gelistet, die aktuell im Index zu dieser Domain zu finden sind
- Intitle:keyword – diese Abfrage zeigt URLs, in deren Title Tag ein bestimmtes Keyword zu finden ist
- Site:domain.de keyword – bei dieser Kombination finde ich URLs einer Domain, die zu einem bestimmten Keyword gelistet sind. Hilfreich zum Beispiel bei der internen Verlinkung, um passende linkgebende Seiten zu finden
- Filetype:xml – findet XML Dateien auf einer Domain, beispielsweise die XML Sitemap. Dies kann natürlich für alle möglichen Dateitypen verwendet werden
- Inurl:keyword – zeigt URLs an, in denen ein bestimmtes Keyword vorkommt. Kann natürlich auch mit dem site: Operator verknüpft werden
Index Cleanup: Jetzt wird aufgeräumt!
Immer wieder tauchen im Netz Meldungen dazu auf, wie große und reichweitenstarke Seiten ihre
Performance bei Suchmaschinen dadurch verbessert haben, dass sie Inhalte entfernt haben.
Erst kürzlich erschien bei Facebook ein Post von Hanns Kronenberg, Senior SEO Manager bei
Chefkoch, zur laufenden SEO Panda Diät.
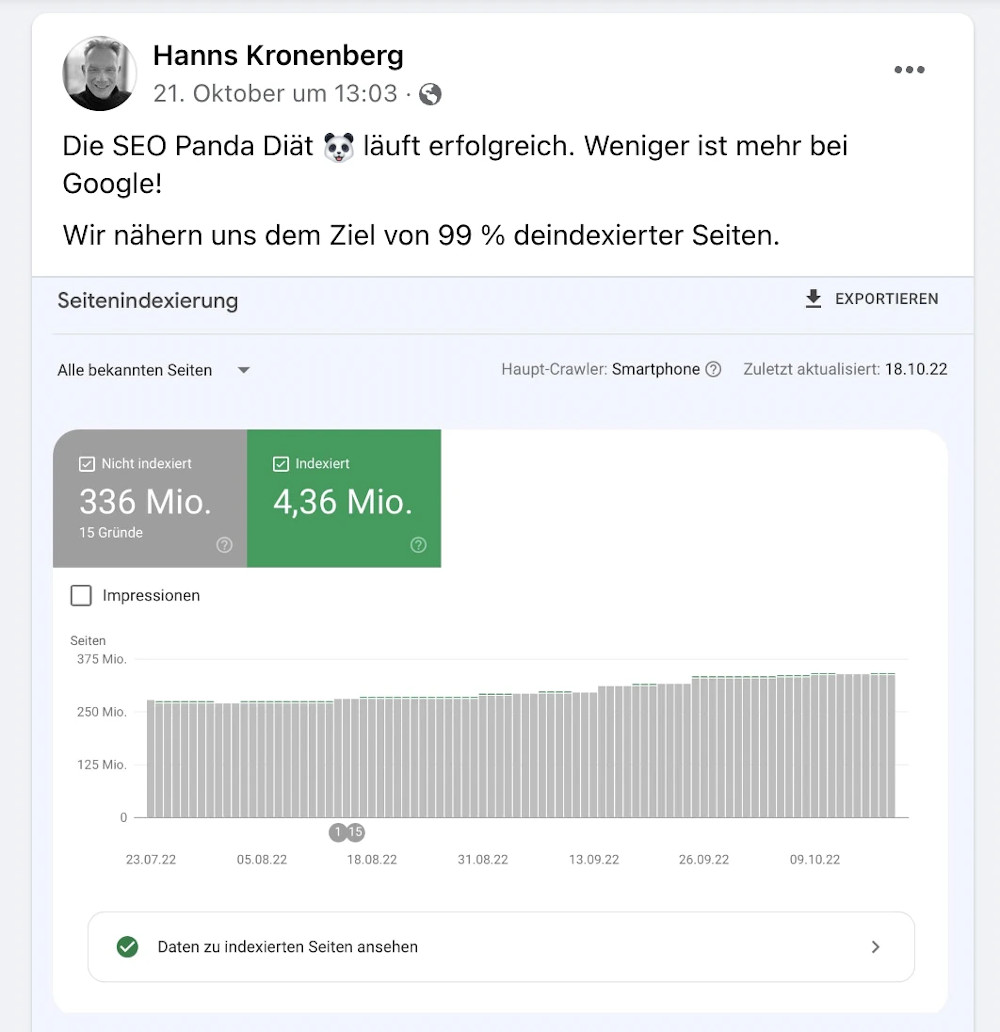
Quelle: https://www.facebook.com/
kronenberg/posts/
Fabian Jaeckert, der ihn dazu für seinen Content Performance Podcast interviewt hat,
zitiert Hanns in einem LinkedIn Post folgendermaßen:
"Ich denke, dass wir besser wissen, welche URLs wertvoll sind und welche weniger Mehrwert haben.
Ich glaube, dass Google das auch herausfinden kann, aber dann testen sie massenhaft und wir
verlieren dadurch die Konstanz und stabile Rankingsignale. Da ist es besser Google zu helfen."
Nach eigener Aussage funktioniert dieses Vorgehen und die wirklich wichtigen Seiten verbessern sich im Ranking.
Welche Seiten gehören denn nicht in den Index? Wie so häufig im SEO lautet die korrekte
Antwort hier „it depends“. Jede SEO Empfehlung muss immer individuell im Hinblick auf die
betreffende Domain bewertet werden. Aber allgemein gesprochen kann man einige Seitentypen
nennen, bei denen es sehr wahrscheinlich ist, dass sie im Google Index nichts verloren haben.
Das wären zum Beispiel Suchergebnisseiten. Es macht keinen Sinn, die eigene Suchergebnisseiten
indexieren zu lassen. Auf Seiten der Domain führt das zu einer Fülle an Thin und Duplicate
Content, da die automatisch generierten Seiten ja nicht individualisiert sind. Auf Seiten
Googles führt es zu der Situation, dass einer Suchmaschine Suchergebnisseiten
geliefert werden, was ungefähr so sinnvoll ist wie ein Tisch beim Italiener zu
bestellen und dann die eigene hausgemachte Pizza mitzubringen.
Gleiches gilt für Filterseiten und Sortierungen, obwohl hier bereits Vorsicht
geboten ist, da es in Einzelfällen eben doch Sinn machen kann, Filterergebnisse indexieren zu lassen.
Nicht im Index sollten natürlich Duplikate von Seiten landen. Diese entstehen oft durch
Parameter-URLs oder andere technische Schwächen. Es geht also gar nicht um das „Abschreiben“
von textlichen Inhalten, sondern oft um technische Mängel, die auf Seiten einer Domain zu
einer Anhäufung doppelter Inhalte führen. Bei einem Crawl lassen sich solche Fehler häufig
sehr leicht finden, da Marker wie doppelte Title Tags oder doppelte Descriptions das Problem deutlich machen.
Ebenfalls aufgrund technischer Schwächen entstehen häufig inhaltsleere Seiten oder Seiten
mit extrem wenig Content (Thin Content). Auch diese sollten im Normalfall nicht im
Google Index landen. Bei einem Crawl können diese neben den bereits genannten Pattern
auch beispielsweise an einer geringen Wortanzahl erkannt werden.
Indexierung steuern - Fazit
Wir sehen: Bei der Suchmaschinenoptimierung geht es nicht nur darum, so gut wie
möglich gefunden zu werden. Es ist auch essentiell wichtig, dass das, was im
Suchmaschinenindex vorliegt, relevant und hochwertig ist. Am besten, Sie schauen
gleich einmal selbst nach mit dem Suchoperator site:ihre-domain.de. Ist jeder Treffer,
den Google zurückliefert, ein Inhalt, den Sie Ihren Besuchern und Kunden präsentieren wollen?
Viel Spaß beim Aufräumen!